We've been seeing a gradual shift in malicious PDF file coding (no surprise there, we know malware authors can and do adapt their techniques).
For a long time, we saw malicious PDF files that were simple enough to allow us to readily decipher the intent of the malicious code — shell code, download/execute, drop and load, et cetera.
Now we're seeing more and more complex obfuscation being used, which requires us to break down the PDF file. This can make an Analyst's daily life more miserable or interesting, especially as the obfuscation can bypass automated analysis tools and even AV detectors.
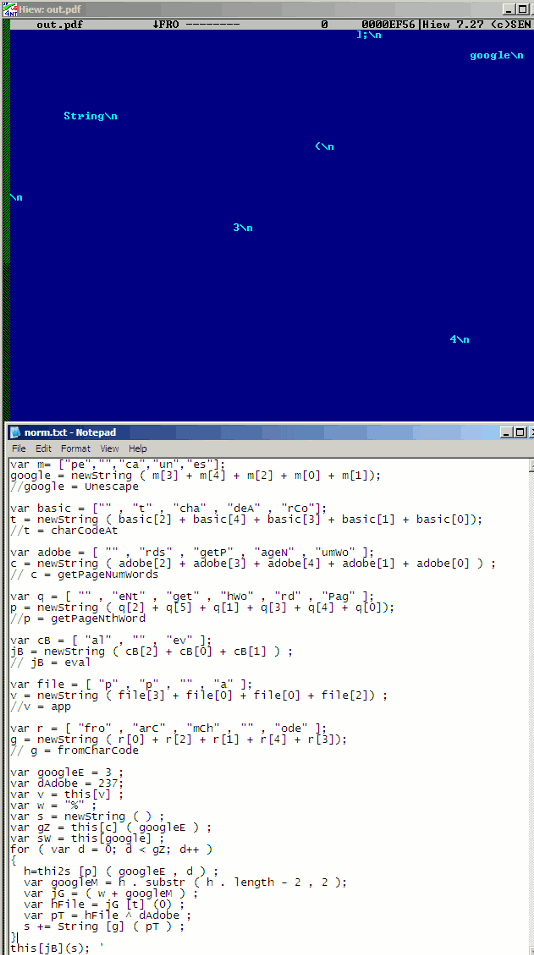
One technique I've encountered in the last few months uses Adobe-specific JavaScript objects such as getPageNthWord and getPageNumWords. Here's a screenshot of one example:
Note how it uses old-school style spacings. Comments in the notepad were added for easier readability.
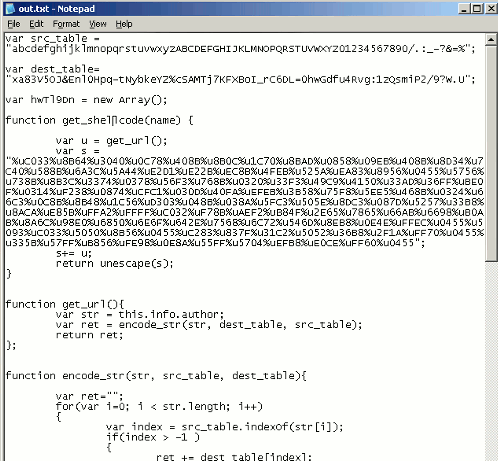
Anyway, once this is normalized, it becomes something much easier to read and analyze:
An interesting analysis about PDF obfuscation is also available at SANS.